Geschreven door CINQ
Building our own augmented reality app – the results
Welcome back! In our previous blogpost: “Building our own augmented reality app,”we explained how we chose Unity and Wikitude as our weapons of choice to explore the world of augmented reality and build our own AR app. In this next episode, we will show you how we put the chosen frameworks into practice. Will we have a working AR app by the end of this blogpost? Keep on reading to find out!
Scene and object recognition in action
We mentioned before that next to recognizing the scene or objects, all that is left is to augment the screen with something. For our demo/prototype we wanted to try a series of things such as:
– show text
– show photos
– play video
– show a 3D model
– have interactions (such as starting a call or opening a website)
We took our own office as a subject (to recognize) and display some basic information about the office and our company.
Furthermore, we also experimented with features such as:
– keeping the augmentation on the screen until the UI is closed
– switching it when a new object or scene is detected
– switching as soon as the scene or object is no longer detected
The result can be seen below in Figure 3.

Figure 3 – the app recognizes the building and shows the UI
The app itself is built in Unity because it enables us to do cross-platform easily and facilitates a lot of core things that we will require anyway. Building a UI in Unity can be a little cumbersome at times as the initial way to get started is to click and drag your UI together.
So, how does the app work?
For now, we have structured the demo in the following way.
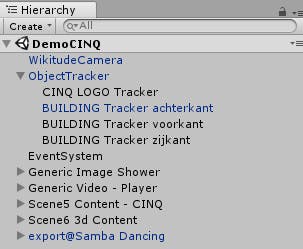
The two main Unity Components used are the WikitudeCamera and ObjectTracker. These are part of the Wikitude API. The Camera object renders the video of your camera inside the App. The ObjectTracker is the logic that takes the camera’s video input and matches it with the point cloud and then determines what to show on your screen.
One of the important properties on the ObjectTracker is the Target Collection. This is where you select your point cloud(s). Keep in mind, a Target Collection can be a collection of point clouds, not just one thing, so it can hold multiple buildings, objects and scenes to detect. In our case, our point cloud holds four models.
As children of the Object Tracker we have defined empty Unity objects with the “Object Trackable” script from the Wikitude API. We will call these trackers from now on. The trackers will activate when certain conditions are met, in our case when a specific model is detected.
While there are four trackers we only track two real-life objects: we detect a logo on our wall in the office and the office building itself. The office building is split into 3 separate planes, because we had some trouble with getting our office building in one model. We believe that with more time spend on making photos and creating a point cloud we could bring this down to a single point cloud.
Each tracker has actions, for example, the CINQ Logo Tracker and one of the building trackers have the properties as shown in Figures 4 and 5.

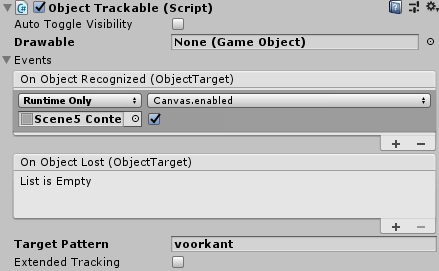
For Figure 4 we have set the Target Pattern to “CINQ LOGO”. This is the name of the model in the point cloud and is the condition on which the object activates. We also set actions for when an object is recognized and when the object is lost. With this configuration the augmented view would be lost when you point your camera at something else.
In this case, we draw a 3D object in the scene and enable the canvas. A canvas in Unity is what renders your UI elements.
For the second object, when the front of our office building is on the camera, we opted to just display a UI element but not remove it when it leaves the camera. The user has to click it away. This makes it easier to interact with UI. You do not have keep the camera pointed towards the object.
For the prototype, we chose to use the visual configuration of the Object Trackable’s in Unity for the sake of speed of prototyping. However when making a real application with many trackers it would pay off to turn this sort of event handling into reusable scripts. So we can perform actions programmatically which makes development and maintaining the app a lot quicker.
We can do whatever we choose with the triggers but for now, we left it to rendering 3D objects and standard UI elements. However, with these same techniques you could render entire virtual worlds over your camera image and make them fully interactable by the user.
We will not go into too much detail about the Unity Canvas elements, but if you want to know more about that have a look at the Canvas documentation of Unity.
Two other components that are of interest are the “Generic Image Shower” and “Generic Video – Player”. These are reusable objects we build in order to easily show a photo or video. The idea behind this is that we turn features like this into components. So we can easily reuse these in any augmented scene we create. Other features that would be good candidates in the future would be audio clips, one for 3D models and possible even generic UI components.
Potential improvements
There are lots of potential paths of improvements for the prototype if we would turn it into a real application.
Localization would be beneficial so we could offer our app in multiple languages. You would achieve this by separating all the text from the presentation layer and have a piece of middleware (unity script) select the text based on the current language selected.
Building the entire UI by hand in the Unity editor can become cumbersome with many different screens and visuals. Ideally, you would want to have generic UI components that make up your screen which gets generated based on code and configuration rather than manual actions in an editor.
Content in these sorts of apps need to be maintained in order to achieve this. The same configuration mentioned above could be obtained from a CMS server which holds the latest definitions of what to show to the end user. This would also enable the app to be easily adapted for multiple use cases. The type of content you should think about is text, videos and/or images to display.
A target collection is small enough that it can be transmitted over an internet connection. So if you would be building an app where internet access is not an issue it would theoretically be possible to create one generic app that reads the point cloud, what to do and its output.
We did it!
So we have achieved our goal. We have an app that is capable of recognizing a building. Furthermore it shows a text and video (once it is recognized). Actually the app can also show photos, open a website and open the phone app with a predefined number. Last but not least it shows a dancing 3D model when recognizing our logo on the wall. Mission accomplished!
Thanks for reading again !
Robin & Bouke
Geschreven door CINQ