Geschreven door Tom de Bruijn
Applicatie Performance Monitoring aansluiten op Splunk IT Service Intelligence
Splunk® IT Service Intelligence (ITSI); De oplossing voor monitoring en analyse, welke aangedreven door machine learning en kunstmatige intelligentie inzicht biedt in de gezondheid van kritieke IT- en zakelijke diensten en hun infrastructuur.
Een uitleg als bovenstaande, gevolgd door de verschillende usecases die Splunk ITSI vervult is wat ik vooral terugvind op het internet. Wat ik nog weinig zie zijn de ervaringen uit de praktijk of technische how-to’s. Zonde, want na een korte kennismaking met ITSI is vaak de reactie: ‘ziet er super gaaf uit’ – kort gevolgd door – ‘maar wat is er nodig voor de inrichting? Hoe werkt het en/of waar moet ik beginnen?’
In dit artikel geef ik antwoord op deze vragen en neem ik jullie graag mee naar het startpunt van ITSI, namelijk het aansluiten van een databron. Ik ga wat meer in op de techniek achter de oplossing en laat aan de hand van een praktijkvoorbeeld zien hoe je de metrieken van Applicatie Performance Monitoring op Splunk ITSI aansluit met daarbij een integratie naar ServiceNow.
High Level Design - APM integratie Splunk ITSI & ServiceNow

Applicatie Performance Monitoring integratie naar Splunk
Als uitgangspunt nemen wij een bestaande databron, de APM-monitoring in een organisatie, links in het HLD als cloud oplossing weergegeven. Dat is de monitoring die door middel van metingen inzicht biedt in de beschikbaarheid- en performance van een applicatie, dienst of een omgeving. Uit de APM-monitoring komen inzichten. Dit zijn de ruwe meetresultaten maar ook al verrijkte data zoals beschikbaarheid- of performance alerts.
Laten we kort stilstaan bij het versturen van de data naar Splunk. Veelal wordt hiervoor gebruik gemaakt van een webhook. Splunk biedt hiervoor zelf de HTTP Event Collector (HEC) aan. Middels HEC wordt de data op een veilige manier naar de Splunk omgeving verstuurd waarnaar het direct in de juiste index wordt opgeslagen. In het HLD noemen wij deze index de APM_Name_Private_index.
Data gereed maken voor Splunk ITSI
Met de alert-data in Splunk is de vervolgstap deze gereed te maken voor Splunk ITSI. Hiervoor is het nodig om de structuur van de data aan te passen naar een structuur die geschikt is voor ITSI. Dit aanpassen van de data naar een geschikt formaat wordt normaliseren genoemd en licht ik graag even toe.
Normaliseren is nodig zodat Splunk ITSI begrijpt wat voor data het binnen krijgt en wat het vervolgens met een event moet doen. Normaliseren lijkt in het begin wat omslachtig, de data zit immers al in Splunk. Het is daarom waarschijnlijk al eerder genormaliseerd tijdens het indexeren, dus waarom moet je het nog een keer aanpassen?
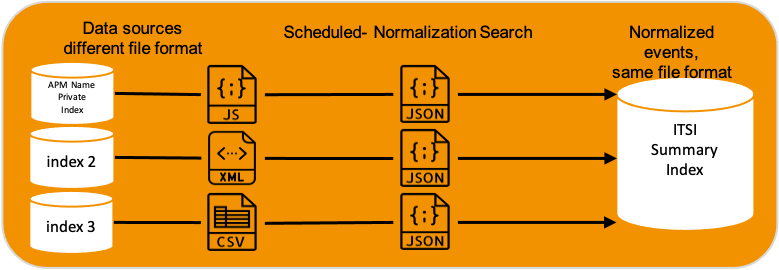
Zie het als volgt; wanneer je meerdere databronnen aansluit op Splunk, dan is de data los van elkaar goed te begrijpen en ook toepasbaar voor ieders doeleinde. Het is echter moeilijk om de data voor hetzelfde doeleinde te gebruiken. Wanneer de data genormaliseerd wordt naar een eenduidig bestandsformaat met daarbij een eenduidige key-value indeling is het voor Splunk ITSI mogelijk wat met de events te kunnen doen.
Belangrijk hierbij is dus dat de key-value indeling door normalisatie hetzelfde wordt. Als voorbeeld: waar in de APM Name Private index links in de afbeelding weergegeven, een veld als responstijd wordt aangeduid met de key-value combinatie performance=value, zal in index 2 dat veld bijvoorbeeld timer=value zijn en in index 3 responsetime=value. Door normalisatie kan dat voor alle drie de databronnen eenduidig aangepast worden naar itsi_duration=value.
Voor het normaliseren van data naar ITSI-events zijn regels en richtlijnen opgesteld, welke door Splunk zijn opgenomen in het Common Interface Model (CIM). Hierin staat beschreven welk veld(key) welk doeleinde(value) heeft en worden er voorbeelden gegeven voor hoe deze toegepast kunnen worden. Los van het CIM zijn er ook Cheat Sheets en Templates beschikbaar gesteld voor veel gebruikte integraties.
Data Normalisatie middels een scheduled search
Het normaliseren – oftewel het hernoemen van velden – gaat in de praktijk middels een Scheduled Search. Zoals de naam al zegt is een Scheduled Search een zoekopdracht in Splunk die je herhaald kan laten uitvoeren. Voor dit doeleinde kijkt de zoekopdracht iedere minuut of er in de APM_Name_Private_index nieuwe events binnen zijn gekomen. Indien dit het geval is worden de velden uit de events middels meerdere eval commando’s aangepast naar ITSI-velden en middels een collect commando weggeschreven naar een aparte summary index, in het HLD genaamd apmname_alerts_itsi_public.
Onderstaand een stuk voorbeeld code SPL waarbij de eval commando’s voor de belangrijkste ITSI-velden worden toegelicht. In de praktijk dient deze code aangepast te worden op de eigen situatie.
```Voorbeeld event*```
Service=Main_Web_App
Type=Availability
DataSource=Login_App
EventId=123456789_1234567890
Business_Service=IOL_GROUP
```Voorbeeld Eval Commando’s```
| eval itsi_entity=Service. "-". Type. "-".DataSource
| eval itsi_correlation_key=itsi_entity
| eval itsi_urgency=Medium, itsi_impact=Low
| eval itsi_event_key=if(isnull(existing_itsi_event_key) OR existing_itsi_event_key=="", itsi_entity. "~".EventId, existing_itsi_event_key)
| eval itsi_tag=mvappend("ITSI", "SNOW")
| eval itsi_business_service=business_service- Itsi_entity
Een entity kan gezien worden als de titel van de melding. - itsi_correlation_key
De correlation_key - in dit geval gelijk aan de entity - zal events in ITSI groeperen en zal vervolgens proberen te kijken of er correlaties mogelijk zijn binnen de entitiy en tussen de entities. Tip: maak een entiteit en dus een correlation_key niet te algemeen, maar ook niet te specifiek. Bij te algemeen krijg je te veel events in 1 entiteit en bij te specifiek, heb je weer te veel entiteiten en dus te weinig events per entiteit. Een belangrijke afweging hierin is dat je wat moet kunnen met de informatie van meerdere events in 1 groep. Voor APM is in dit geval de entiteit dus Service-TypeAlert-Stapnaam, bijvoorbeeld bedrijfsapplicatie-beschikbaarheid-inloggen. - Itsi_urgency en itsi_impact
Hiermee wordt de urgentie alsmede de impact aangegeven voor het event. Een melding wordt afgesloten (positieve alert) door beide als status low mee te geven. - itsi_event_key
Om nieuwe events aan te maken, maar ook om op een bestaand event door te schrijven wordt gebruik gemaakt van een event_key. Ieder nieuw event heeft een unieke eventID. Tijdens de normalisatie wordt middels een correlatie zoekopdracht gekeken of er nog een openstaand probleem is. Bijvoorbeeld een performance melding met als impact Warning. Als bij een nieuw event de impact/urgentie wijzigt, bijvoorbeeld naar een Critical status, wordt op dat event doorgeschreven. In dat geval wordt dan de existing_itsi_event_key gebruikt. - itsi_tag
eval itsi_tag=mvappend("ITSI", "SLACK","SNOW")
Middels een tag wordt aangegeven welke integratie opgepakt moet worden. In dit voorbeeld wordt het event opgenomen door ITSI en wordt ook de integratie Service Now Now-IT gestart. Er zijn echter meerdere standaard integraties mogelijk, zoals naar Slack of Teams, maar ook een custom integratie zoals naar TopDesk. - Itsi_business_service
| eval itsi_business_service=business_service
Een business service komt in dit geval overeen met de business service in Service Now en zal er dus voor zorgen dat dit evenement op juiste manier gekoppeld wordt aan SNOW. Tijdens het normaliseren is het dus mogelijk om custom velden als deze toe te voegen.
Overige velden kunnen nog zijn: itsi_instruction, itsi_summary, itsi_message. Dit zijn velden met aanvullende informatie, een oplos instructie, samenvatting, en uitgebreidere uitleg van de melding kunnen hier worden opgegeven.
Van Splunk naar Splunk ITSI
Tijdens de normalisatie is het event middels het collect commando verstuurd naar de apmname_alerts_itsi_public summary index. Vanuit deze public index wordt door een correlation search de events opgenomen door Splunk ITSI. Dit is een standaard functionaliteit binnen Splunk ITSI en kan gezien worden als een macro die een index scant op nieuwe events en de integratie naar Splunk ITSI start. Eenmaal in Splunk ITSI komen de events binnen als “notable event”. Een notable event kan gezien worden als een losstaand alert. Wanneer een alert weer een positieve status heeft, bijvoorbeeld inloggen applicatie was onbeschikbaar en nu weer beschikbaar, wordt het event afgesloten en toegevoegd als Episode. Op zowel de losstaande notable events als de episodes worden correlatie zoekopdrachten gedaan en kunnen incidenten gestart worden. Deze correlaties binnen een databron als tussen databronnen toont de kracht van ITSI.
Voorbeeld: uit een notable event wordt een incident aangemaakt, bijvoorbeeld applicatie 1 is traag bij opstarten (performance), of inloggen werkt niet (beschikbaarheid). Uit episodes kunnen middels deep-dives alerts komen als, de afgelopen 4 maandag ochtenden was het inloggen traag tussen 08:00 en 10:00 of inloggen werkt iedere dinsdag tussen 07:00-08:00 niet. Ook kunnen correlaties gelegd worden tussen databronnen, een incident als, deze servers hadden een hoog CPU, gelijktijdig was de applicatie traag.
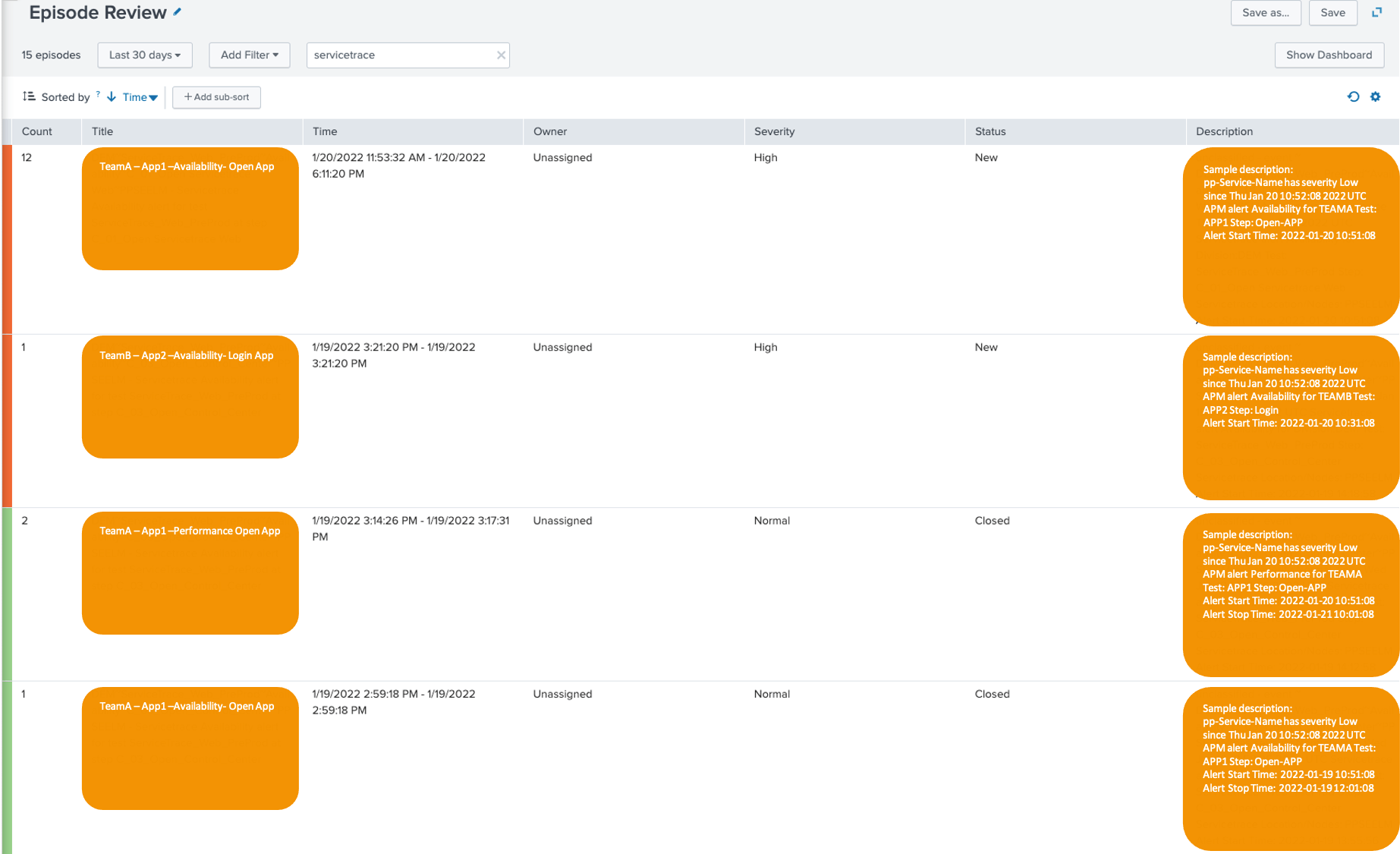
Het incident wordt dus aangemaakt binnen ITSI. Een overzicht van de openstaande en/of gesloten events is terug te vinden in de Episode Review:
Episode Review – Splunk ITSI
Van Splunk ITSI naar ServiceNow
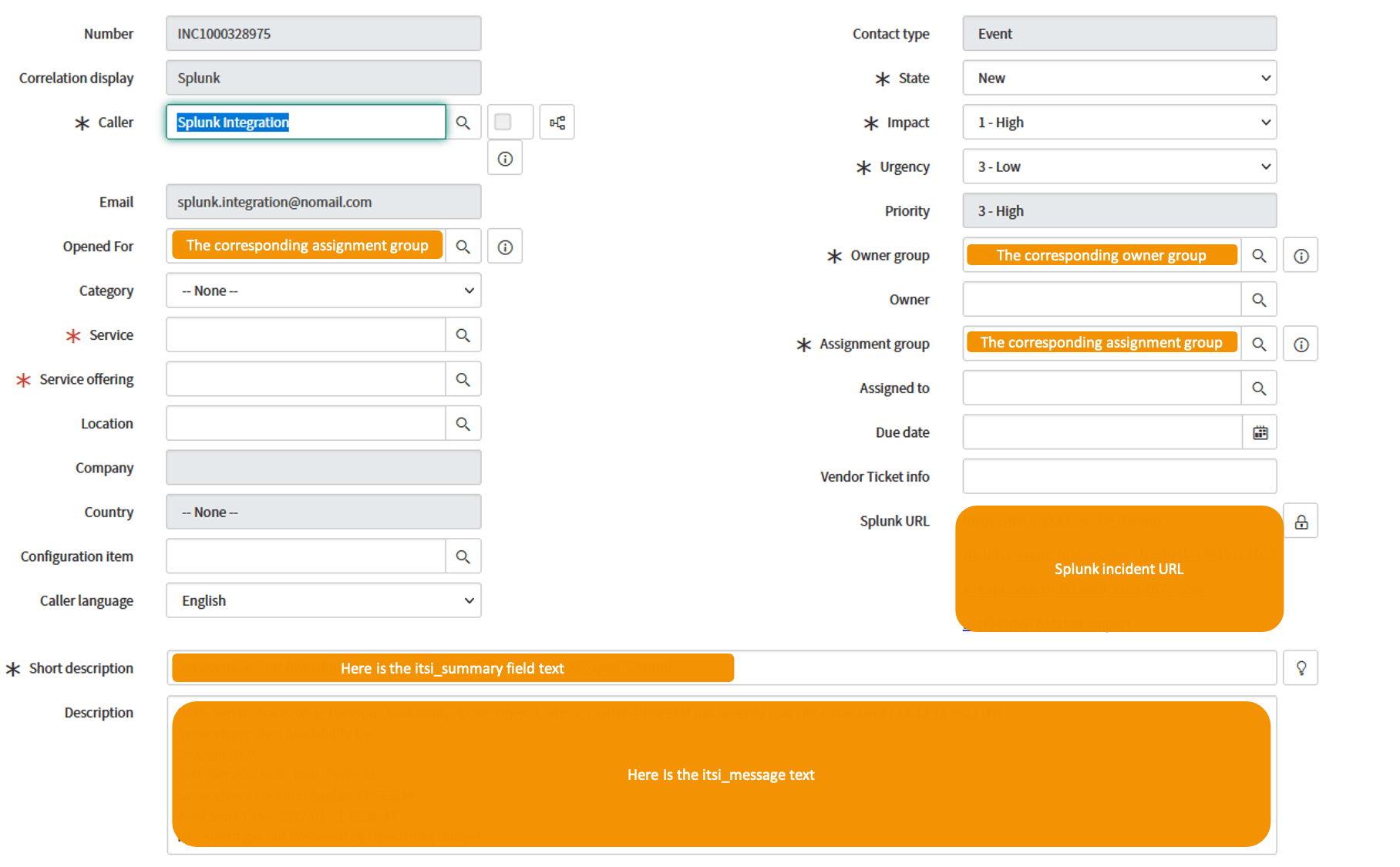
Voor de integratie naar ServiceNow wordt een standaardoplossing binnen ITSI aangeboden, zie hiervoor de Splunk Docs - ITSI SNOW. In ons voorbeeld is in 1 van de besproken velden, de itsi_tag aangegeven om de integratie naar ServiceNow te starten. Vanuit Splunk ITSI wordt middels een XML/SOAP call een incident in ServiceNow aangemaakt en/of voorzien van een nieuwe status. De integratie tussen Splunk en ServiceNow werkt bidirectioneel. Indien in ServiceNow dus een update wordt doorgevoerd, wordt deze ook naar Splunk verzonden en vice versa.
Event in ServiceNow – aangemaakt door Splunk ITSI
Samengevat
In dit artikel heb ik jullie een inkijkje gegeven over het aansluiten van data op Splunk ITSI. Wij hebben gebruikmakend van HEC, alert data van een APM-product gestuurd naar een Splunk omgeving. Middels een saved search hebben wij vervolgens de event data genormaliseerd naar een Splunk ITSI event. Tijdens het normaliseren is middels eval commando’s aangegeven wat voor event (entiteit) het betreft en wat de status (urgentie/impact) is. Ook is aangegeven onder welke groep (correlation_key) het nieuwe notable event valt en of het gaat om een nieuwe gebeurtenis (event_key) of een vervolg (existing_event_key) op een bestaande gebeurtenis betreft. Doordat in de Tag is aangegeven, ook de koppeling naar ServiceNow Now-IT te starten, zal vanuit ITSI ook direct het evenement hiernaartoe doorgestuurd worden en gekoppeld worden aan de business_service, met daarin mogelijk een instructie, samenvatting en aanvullend bericht.
Persoonlijk vind ik Splunk ITSI een gave oplossing, na al dan niet wat handmatig instellen in het begin, kan vervolgens veel waarde gehaald worden uit de automatische correlaties en berichtgeving die eruit volgt.
Geschreven door CINQ